PostgreSQL et SAS Viya : Le choc des cultures (Casse, Schémas et Guillemets)
Michael 235 vues
Niveau de difficulté
Confirmé
Publié le :
Le conseil de l'expert
Michael
Travailler avec PostgreSQL dans un environnement SAS Viya, c'est un peu comme faire cohabiter deux maniaques du rangement qui n'ont pas les mêmes règles. PostgreSQL est intransigeant sur la casse (minuscules/majuscules), tandis que SAS veut tout standardiser.
Si vous obtenez une erreur 'Table not found', ne cherchez pas un problème réseau. Dans 90% des cas, c'est un conflit de guillemets. Mon conseil ? Soyez explicites. Définissez vos schémas dans la connexion (CASLIB) et protégez vos noms de tables avec des guillemets doubles. C'est verbeux au début, mais c'est la seule façon de garantir des pipelines de données robustes et maintenables.
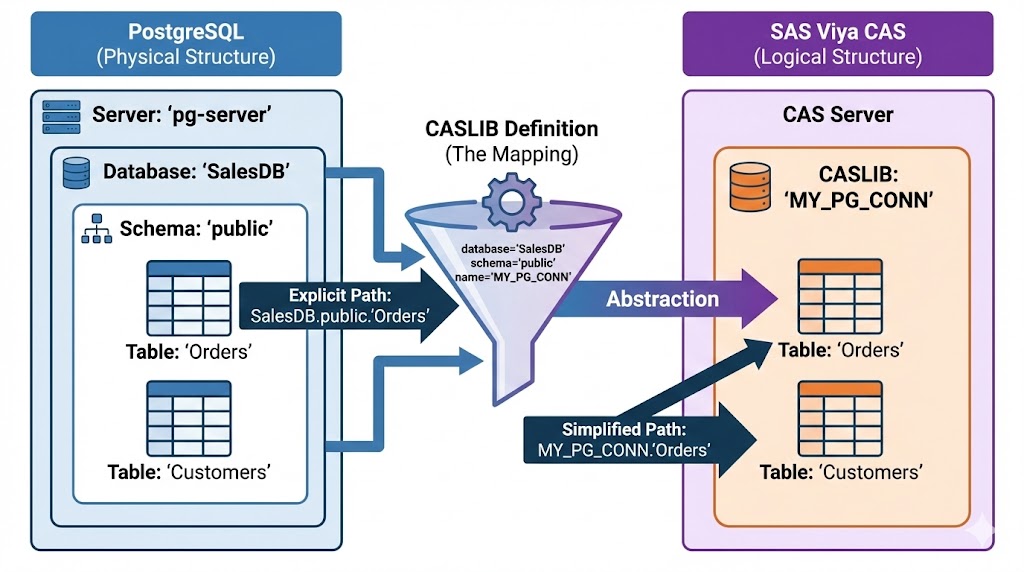
Si l'abstraction du niveau database.schema via la CASLIB est la règle générale dans Viya™, PostgreSQL ajoute une couche de complexité supplémentaire : il est extrêmement pointilleux sur la casse (Case Sensitivity).
Erreur : Relation "VENTES_2024" does not exist. (Car la table s'appelle ventes_2024).
La Solution : La Double protection
Pour réussir une requête fedSql.execDirect sur PostgreSQL, vous devez être explicite à deux niveaux :
Structurel : Mapper Database + Schema dans la CASLIB.
Syntaxique : Utiliser des guillemets doubles "" pour protéger les noms de tables/colonnes Postgres.
Voici le "Template Parfait" pour PostgreSQL :
proc cas;
/* ÉTAPE 1 : La définition précise de la CASLIB
C'est ici qu'on gère le "Database.Schema" */
table.addCaslib /
name="MY_PG_CONN"
dataSource={
srcType="postgres",
server="pg-server",
/* PostgreSQL exige souvent de préciser la base ET le schéma */
database="MaBaseCommerciale",
schema="public"
};
/* ÉTAPE 2 : La requête blindée
Notez l'usage des QUOTES SIMPLES à l'extérieur
et des QUOTES DOUBLES à l'intérieur */
fedSql.execDirect /
query='select
"id_client",
"date_vente"
from MY_PG_CONN."MaTableVentes"
where "montant" > 1000';
quit;
1
PROC CAS;
2
/* ÉTAPE 1 : La définition précise de la CASLIB
3
C'est ici qu'on gère le "Database.Schema" */
4
TABLE.addCaslib /
5
name="MY_PG_CONN"
6
dataSource={
7
srcType="postgres",
8
server="pg-server",
9
/* PostgreSQL exige souvent de préciser la base ET le schéma */
10
database="MaBaseCommerciale",
11
schema="public"
12
};
13
14
/* ÉTAPE 2 : La requête blindée
15
Notez l'usage des QUOTES SIMPLES à l'extérieur
16
et des QUOTES DOUBLES à l'intérieur */
17
fedSql.execDirect /
18
query='select
19
"id_client",
20
"date_vente"
21
from MY_PG_CONN."MaTableVentes"
22
where "montant" > 1000';
23
QUIT;
Pourquoi c'est critique avec PostgreSQL ?
Sur SQL Server ou Oracle, on s'en sort souvent sans guillemets car ils sont moins sensibles à la casse par défaut (ou configurés pour ignorer la casse). Mais PostgreSQL est strict.
Si votre table a été créée via un script généré par un outil (type Hibernate, pgAdmin), elle s'appelle souvent "MaTable".
Si ça ne marche pas, c'est probablement la casse. Mettez des guillemets doubles autour du nom de la table, et englobez toute votre requête query dans des guillemets simples.
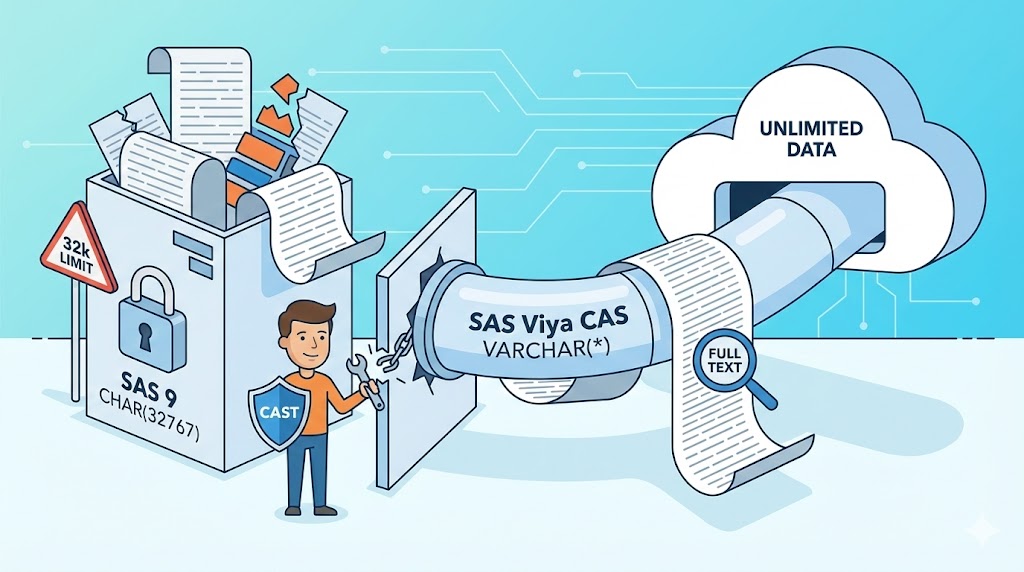
Briser le Mur des 32k : Gérer les textes longs dans CAS
CAS VARCHAR (Variable) : Limite théorique ~2 Go par cellule ! Il n'utilise que l'espace nécessaire.
Si vos données sont tronquées dans CAS, c'est généralement parce que, par habitude ou par défaut, la colonne a été définie comme un vieux CHAR fixe.
La Solution : Soyez explicite dans vos CAST
Pour forcer CAS à utiliser sa capacité de stockage "longue", vous devez définir explicitement la colonne cible en VARCHAR lors de vos transformations SQL.
Vous pouvez spécifier une taille précise (ex: 100 000) ou utiliser VARCHAR(*) pour demander à CAS d'allouer dynamiquement le maximum nécessaire.
Voici comment transformer une colonne de texte limitée en un champ "grand format" via fedSql.execDirect :
proc cas;
/* On suppose que l'on a une table source 'MES_DONNEES_SOURCE'
avec une colonne 'commentaire_client' qui risque d'être longue */
fedSql.execDirect /
query='create table CASUSER.RESULTAT_TEXTE_LONG {options replace=true} as
select
id_client,
date_reclamation,
/* On force la conversion (CAST) vers un VARCHAR très grand */
CAST(commentaire_client AS VARCHAR(100000)) as commentaire_complet,
from CASUSER.MES_DONNEES_SOURCE';
quit;
1
PROC CAS;
2
/* On suppose que l'on a une table source 'MES_DONNEES_SOURCE'
3
avec une colonne 'commentaire_client' qui risque d'être longue */
4
5
fedSql.execDirect /
6
query='create table CASUSER.RESULTAT_TEXTE_LONG {options replace=true} as
7
select
8
id_client,
9
date_reclamation,
10
11
/* On force la conversion (CAST) vers un VARCHAR très grand */
12
CAST(commentaire_client AS VARCHAR(100000)) as commentaire_complet,
13
14
from CASUSER.MES_DONNEES_SOURCE';
15
QUIT;
En exécutant ceci, la table résultante RESULTAT_TEXTE_LONG en mémoire contiendra l'intégralité des textes, même s'ils font 80 000 caractères.
Lors d'un execDirect, la conversion est généralement automatique. Mais si vous faites des jointures entre une table chargée en mémoire (CAS table) et une table PostgreSQL distante :
Assurez-vous que les clés de jointure sont de types compatibles.
Parfois, il faut caster explicitement côté SQL : CAST("mon_id" AS DOUBLE PRECISION).
Comme nous l'avons vu, les blocages les plus fréquents ne viennent pas de la complexité des algorithmes, mais de la "grammaire" de la connexion aux données. En acceptant de perdre le contrôle direct sur la hiérarchie database.schema au profit de l'abstraction des CASLIBs, et en maîtrisant la rigueur syntaxique imposée par PostgreSQL (notamment cette fameuse gestion des guillemets), vous débloquez la véritable puissance de la plateforme.
Soyez explicite sur les types et la casse (Rigueur).
Laissez le moteur MPP gérer le volume (Performance).
Une fois ces ajustements techniques maîtrisés, la frustration syntaxique laisse place à la satisfaction de voir des traitements de plusieurs millions de lignes s'exécuter en quelques secondes.
Avertissement important
Les codes et exemples fournis sur WeAreCAS.eu sont à but pédagogique. Il est impératif de ne pas les copier-coller aveuglément sur vos environnements de production. La meilleure approche consiste à comprendre la logique avant de l'appliquer. Nous vous recommandons vivement de tester ces scripts dans un environnement de test (Sandbox/Dev). WeAreCAS décline toute responsabilité quant aux éventuels impacts ou pertes de données sur vos systèmes.
SAS et tous les autres noms de produits ou de services de SAS Institute Inc. sont des marques déposées ou des marques de commerce de SAS Institute Inc. aux États-Unis et dans d'autres pays. ® indique un enregistrement aux États-Unis. WeAreCAS est un site communautaire indépendant et n'est pas affilié à SAS Institute Inc.
Ce site utilise des cookies techniques et analytiques pour améliorer votre expérience.
En savoir plus.