Bei der Datenmanipulation in SAS© ist es sehr üblich, Informationen aus einer Haupttabelle (Quelldataset) auf der Grundlage einer spezifischen Liste von IDs zu extrahieren, die in einer anderen Tabelle enthalten ist.
Wenn Sie bereits vergeblich versucht haben, eine WHERE-Klausel zu schreiben, die direkt auf eine andere Tabelle verweist, erklärt Ihnen dieser Artikel die korrekte Syntax, um diesen Vorgang effizient mit PROC SQL durchzuführen.
Das Szenario
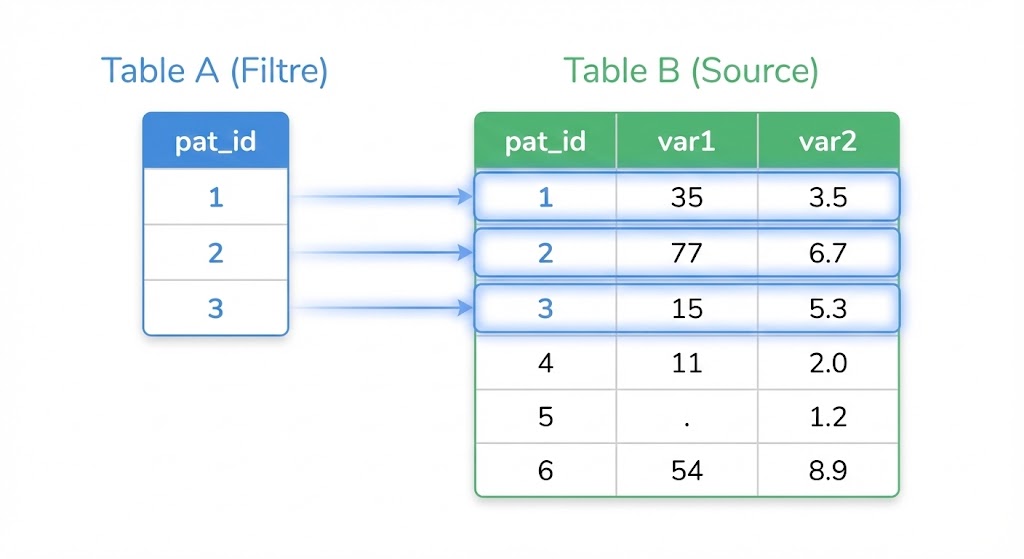
Stellen wir uns vor, wir haben zwei Tabellen:
Tabelle A: Eine eingeschränkte Liste von Patienten-IDs (pat_id). Das ist unser Filter.
Tabelle B: Eine vollständige Datenbank mit Messungen (var1, var2) für viele Patienten.
Das Ziel: Ein neues Dataset erstellen, das nur die Zeilen aus Tabelle B enthält, deren pat_id in Tabelle A vorhanden ist.
Der häufige Fehler
Intuitiv könnte man eine Abfrage schreiben wollen, die so aussieht:
... where pat_id in tableA;
Allerdings erlaubt SAS© nicht, eine rohe Tabelle direkt in einer IN-Klausel zu referenzieren. Man muss eine sogenannte Unterabfrage (sub-query) verwenden.
Die Lösung: Die Unterabfrage
Damit die WHERE-Klausel funktioniert, muss sie die Variable pat_id mit einer Liste von Werten vergleichen, die von einer SELECT-Abfrage zurückgegeben wird.
Hier ist die korrekte Syntax:
Wie funktioniert das?
Die Klammer (Unterabfrage): Der Code select pat_id from table_a wird zuerst ausgeführt. Er generiert die Liste der zu behaltenden IDs (hier: 1, 2, 3).
Die Hauptabfrage: SAS© durchläuft dann die table_b und behält nur die Zeilen, bei denen die pat_id einer der von der Unterabfrage gefundenen IDs entspricht.
Endergebnis
Wenn Sie den obigen Code ausführen, erhalten Sie die folgende Tabelle want, die eine exakte Kopie der Daten aus Tabelle B ist, gefiltert nach Tabelle A:
| pat_id | var1 | var2 |
| 1 | 35 | 3.5 |
| 2 | 77 | 6.7 |
| 3 | 15 | 5.3 |
Diese Methode ist sauber, effizient und standardisiert, um relationale Daten in SAS© über die SQL-Sprache zu filtern.