Es muy común, al manipular datos en SAS©, tener que extraer información de una tabla principal (dataset fuente) basándose en una lista específica de identificadores contenida en otra tabla.
Si alguna vez ha intentado escribir una cláusula WHERE que haga referencia directa a otra tabla sin éxito, este artículo le explica la sintaxis correcta para realizar esta operación de manera eficiente con PROC SQL.
El Escenario
Imaginemos que tenemos dos tablas:
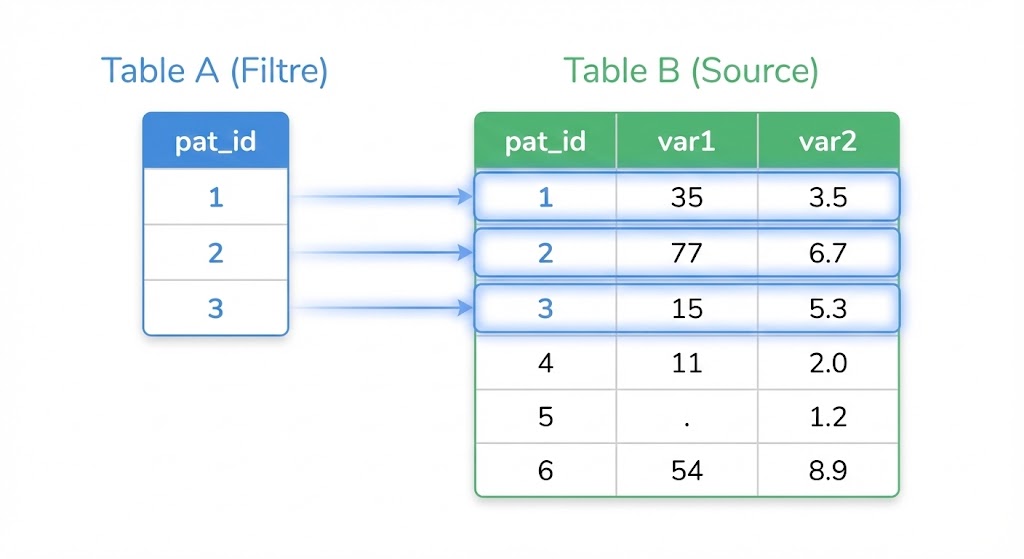
Tabla A: Una lista restringida de identificadores de pacientes (pat_id). Este es nuestro filtro.
Tabla B: Una base de datos completa que contiene mediciones (var1, var2) para muchos pacientes.
El objetivo: Crear un nuevo dataset que contenga únicamente las filas de la Tabla B cuyo pat_id esté presente en la Tabla A.
El Error Frecuente
Intuitivamente, uno podría querer escribir una consulta parecida a esta:
... where pat_id in tableA;
Sin embargo, SAS© no permite hacer referencia a una tabla en bruto directamente en una cláusula IN. Es necesario utilizar lo que se llama una subconsulta (sub-query).
La Solución: La Subconsulta
Para que la cláusula WHERE funcione, debe comparar la variable pat_id con una lista de valores devuelta por una consulta SELECT.
Aquí está la sintaxis correcta:
¿Cómo funciona esto?
El paréntesis (Subconsulta): El código select pat_id from table_a se ejecuta primero. Genera la lista de IDs a conservar (aquí: 1, 2, 3).
La consulta principal: SAS© luego recorre la table_b y solo conserva las filas donde el pat_id corresponde a uno de los IDs encontrados por la subconsulta.
Resultado Final
Al ejecutar el código anterior, obtendrá la siguiente tabla want, que es una copia exacta de los datos de la Tabla B, filtrada por la Tabla A:
| pat_id | var1 | var2 |
| 1 | 35 | 3.5 |
| 2 | 77 | 6.7 |
| 3 | 15 | 5.3 |
Este método es limpio, eficiente y estandarizado para filtrar datos relacionales en SAS© a través del lenguaje SQL.